Druid是一个开源的、面向列的分布式数据存储系统,专为实时查询和分析大规模事件流数据而设计。它结合了数据仓库、时间序列数据库和搜索系统的特点,能够高效地摄取、存储和查询海量实时数据。Druid的核心优势在于其低延迟的数据摄取和高性能的OLAP查询能力,特别适用于处理TB级甚至PB级的实时数据。
Druid的关键特性
- 列式存储:Druid采用列式存储结构,支持高效的数据压缩和快速聚合查询。
- 分布式架构:数据自动分片和复制,确保高可用性和水平扩展性。
- 实时数据摄取:支持从Kafka、Kinesis等流数据源实时摄取数据,延迟可低至毫秒级。
- 多维分析:支持灵活的多维度数据切片和钻取,并集成近似查询算法(如HyperLogLog)。
Twitter大数据团队如何应用Druid分析ZB级实时数据
Twitter作为全球领先的社交媒体平台,每天产生数PB的实时数据(如推文、点击流、广告交互等)。其大数据团队采用Druid构建了实时数据分析平台,以支持业务监控、用户行为分析和广告效果评估等场景。具体应用方式如下:
1. 实时数据摄取与处理
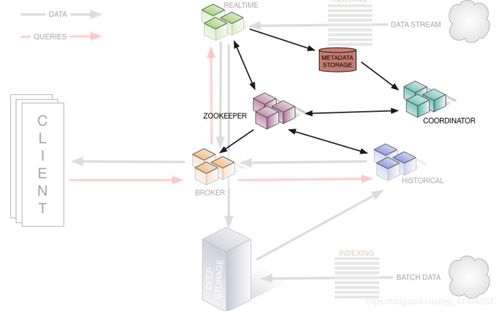
Twitter通过Kafka集群收集实时数据流(如用户活动事件),并利用Druid的索引服务(Indexing Service)直接摄取数据。Druid的实时节点(Realtime Node)负责处理流入的数据,并将其转换为列式格式存储于深度存储(如HDFS或S3)中。通过分片和并行处理,Druid能够高效处理ZB级数据流。
2. 分布式存储与查询优化
Druid的数据节点(Historical Node)存储已处理的数据段(Segment),并利用ZooKeeper协调数据分布和查询路由。Twitter团队通过水平扩展Druid集群,将数据分散到数百个节点上,以应对高并发查询。同时,Druid的查询节点(Broker Node)对查询进行优化和路由,确保低延迟响应。
3. 实时分析与可视化
Twitter利用Druid的SQL接口和REST API,构建了实时仪表盘和告警系统。例如,团队可以实时分析用户推文的互动趋势、广告点击率或异常流量检测。通过Druid的高性能聚合查询,Twitter能够在秒级内完成对数十亿条数据的多维度分析。
4. 数据治理与成本控制
为管理ZB级数据,Twitter团队通过Druid的数据生命周期管理功能,自动归档或删除旧数据,并利用分层存储(热数据存于SSD,冷数据存于对象存储)降低成本。同时,通过监控Druid集群的负载和性能,团队持续优化资源配置。
总结
Druid凭借其分布式架构和实时处理能力,成为Twitter大数据团队处理ZB级实时数据的核心工具。通过高效的数据摄取、存储和查询机制,Druid帮助Twitter实现了从海量数据中快速提取价值,支撑了关键业务的实时决策。对于其他面临类似大规模实时数据分析挑战的企业,Druid同样是一个值得考虑的选择。