在数字化浪潮席卷全球的今天,大数据已成为驱动各行各业创新与增长的关键引擎。无论是企业决策、产品研发,还是市场营销,数据的力量无处不在。对于初学者而言,从零开始学习大数据可能会感到迷茫,但只要有清晰的路径和系统的规划,任何人都能逐步掌握这一重要技能。本文将为你提供一份详实的学习路线图,并重点解析数据处理的核心环节,助你顺利开启大数据之旅。
第一阶段:夯实基础——理论知识与技能准备
学习大数据的第一步是建立坚实的理论基础。理解大数据的基本概念至关重要,包括大数据的“4V”特征(Volume、Velocity、Variety、Veracity),以及其在商业、科学和社会中的应用场景。需要掌握统计学和概率论的基础知识,这是数据分析的基石。编程能力是处理数据的必备工具,建议从Python或Java入手,因为它们在大数据生态系统中应用广泛。Python因其简洁语法和丰富的数据科学库(如NumPy、Pandas)而备受推崇。
第二阶段:掌握核心——数据处理技术与工具
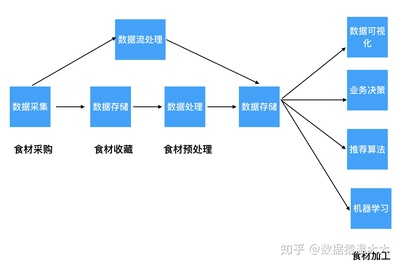
数据处理是大数据学习中的核心环节,涉及数据收集、清洗、存储和分析等多个步骤。在这一阶段,你需要重点学习以下内容:
- 数据收集与集成:了解如何从数据库、API、日志文件等来源获取数据,并学习使用工具如Apache Kafka进行实时数据流处理。
- 数据清洗与预处理:这是确保数据质量的关键步骤。你需要掌握处理缺失值、异常值和重复数据的方法,并学习使用Python的Pandas库或SQL进行数据清洗。
- 数据存储与管理:熟悉关系型数据库(如MySQL)和非关系型数据库(如HBase、MongoDB)。特别是要深入学习Hadoop生态系统,包括HDFS(分布式文件系统)和Hive(数据仓库工具),它们是处理海量数据的基石。
- 数据分析与计算:学习使用Spark进行大规模数据处理,它比传统的MapReduce更高效。掌握基本的机器学习算法(如分类、聚类)和可视化工具(如Tableau、Matplotlib),将数据转化为见解。
第三阶段:实践提升——项目经验与持续学习
理论学习之外,动手实践是巩固技能的最佳方式。建议从简单的项目开始,例如分析公开数据集(如Kaggle上的竞赛数据),逐步尝试构建端到端的数据处理流程。参与开源项目或实习也能提供宝贵的实战经验。大数据技术日新月异,保持持续学习至关重要,可以关注行业博客、在线课程(如Coursera、edX上的大数据专项)和技术社区(如Stack Overflow)。
福利分享:资源推荐与学习工具
为助力你的学习旅程,这里特别分享一些免费资源:
- 在线课程:Coursera的“Big Data Specialization”(约翰霍普金斯大学)提供系统化教学。
- 书籍推荐:《大数据时代》帮助你理解概念,《利用Python进行数据分析》则提供实用指南。
- 实践平台:Databricks社区版提供免费的Spark环境,可用于实验和项目开发。
- 数据集:UCI机器学习库和Google数据集搜索提供丰富数据源,供你练习处理技巧。
从零学习大数据需要耐心和坚持,但通过分阶段的理论学习、核心技能掌握以及持续实践,你将能够逐步解锁数据处理的能力,为未来职业生涯增添强大竞争力。记住,大数据不仅是技术,更是一种思维——用数据驱动决策,让信息创造价值。开始行动吧,数据世界的大门已为你敞开!