从数据到洞见:数据科学家的日常数据处理实践
引言:数据作为新石油的挑战
在数据驱动的时代,数据科学家被誉为“21世纪最性感的职业”。与光鲜的称号形成鲜明对比的是,数据科学家日常工作中约60-80%的时间都花在了数据处理上——这项看似枯燥却至关重要的任务。数据处理不仅是机器学习项目的基础,更是决定模型成败的关键环节。
数据科学家的典型数据处理流程
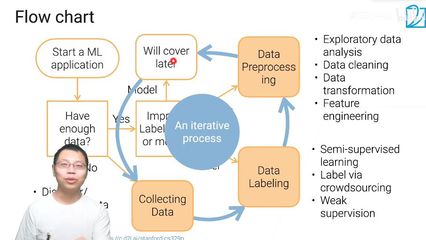
1. 数据收集与理解
每天开始,数据科学家可能面对的是各种来源的数据:
- 数据库查询(SQL)
- API接口调用
- 日志文件解析
- 第三方数据集
这一阶段的核心是理解数据的“故事”——数据的含义、采集方式、潜在的偏差以及业务背景。一个优秀的数据科学家会像侦探一样,仔细审查每个字段的含义和关系。
2. 数据清洗:去除杂质
数据清洗是数据处理中最耗时的环节,包括:
- 处理缺失值:根据情况选择删除、填充(均值、中位数、众数)或使用高级插补方法
- 异常值检测:使用统计方法(如IQR规则)或可视化方法识别并处理异常数据点
- 数据类型转换:确保数值、类别、时间等数据类型正确
- 重复数据删除:识别并移除重复的记录
3. 特征工程:创造价值
特征工程是机器学习中的“艺术”,数据科学家通过以下方式创造有预测能力的特征:
- 特征提取:从原始数据中提取有意义的信息(如从日期中提取星期几、季节)
- 特征变换:对数值特征进行标准化、归一化或对数变换
- 特征组合:将多个特征组合成新特征(如“收入/年龄”比率)
- 类别编码:对分类变量进行独热编码、标签编码或目标编码
4. 数据分割与验证
为避免过拟合,数据科学家需要:
- 将数据分为训练集、验证集和测试集
- 采用交叉验证等策略评估模型稳定性
- 确保数据分割不会引入时间泄漏或分布偏差
实用工具与技术栈
现代数据科学家依赖于丰富的工具生态系统:
Python生态
- Pandas:数据操作的瑞士军刀,提供DataFrame数据结构和丰富的处理方法
- NumPy:高效数值计算的基础
- Scikit-learn:提供完整的数据预处理模块
- Dask/Modin:处理大规模数据的并行计算框架
可视化工具
- Matplotlib/Seaborn:基础可视化
- Plotly:交互式可视化
- Tableau/Power BI:商业智能报告
工作流管理
- Jupyter Notebook:探索性数据分析的标准环境
- Airflow/Luigi:自动化数据处理流水线
日常挑战与解决方案
挑战1:大规模数据处理
当数据量超过内存限制时,数据科学家需要:
- 采用分批处理策略
- 使用数据采样技术
- 利用分布式计算框架(如Spark)
挑战2:非结构化数据处理
对于文本、图像等非结构化数据,需要:
- 自然语言处理技术(分词、向量化)
- 计算机视觉预处理(图像缩放、增强)
- 深度学习特征提取
挑战3:实时数据处理
在流数据场景下:
- 使用流处理框架(如Kafka、Spark Streaming)
- 设计增量更新策略
- 实现低延迟特征计算
最佳实践与经验分享
- 文档化一切:记录每个数据处理步骤的决策和原因
- 可复现性优先:确保数据处理流程可以完全复现
- 版本控制:对数据和代码都使用版本控制(如DVC、Git LFS)
- 测试驱动:为数据处理代码编写单元测试
- 自动化流水线:将重复的数据处理任务自动化
数据处理作为核心竞争力
数据处理远不止是“清洗数据”那么简单。它是连接原始数据与业务价值的桥梁,是数据科学家的核心技能之一。在机器学习2.5时代,随着AutoML等自动化工具的发展,数据科学家从繁琐的调参工作中解放出来,反而更需要专注于数据质量、特征工程和数据流水线的构建——这些是自动化工具难以替代的人类智慧。
每天面对杂乱无章的数据,通过系统性的处理将其转化为清晰的信号,最终驱动业务决策,这正是数据科学家工作的魅力所在。数据处理不再是简单的准备工作,而是整个数据科学流程中创造最大价值的环节之一。
注:本文基于实际数据科学工作场景编写,适用于希望了解数据科学家日常工作或正在进入该领域的读者。数据处理的具体技术会随工具发展而演进,但基本原则和思维方式具有持久价值。